Overview
In recent years, a number of reinforcement learning (RL) methods have been proposed to explore complex environments which differ across episodes, such as procedurally-generated video games or embodied AI tasks. In this work, we show that the effectiveness of these methods critically relies on a count-based episodic term in their exploration bonus. As a result, despite their success in relatively simple, noise-free settings, these methods fall short in more realistic scenarios where the state space is vast and prone to noise. To address this limitation, we introduce Exploration via Elliptical Episodic Bonuses (E3B), a new method which extends count-based episodic bonuses to continuous state spaces and encourages an agent to explore states that are diverse under a learned embedding within each episode. The embedding is learned using an inverse dynamics model in order to capture controllable aspects of the environment. Our method sets a new state-of-the-art across 16 challenging tasks from the MiniHack suite, without requiring task-specific inductive biases. E3B also matches existing methods on sparse reward, pixel-based Vizdoom environments, and outperforms existing methods in reward-free exploration on Habitat, demonstrating that it can scale to high-dimensional pixel-based observations and realistic environments.
Introduction
Exploration in environments with sparse rewards is a fundamental challenge in reinforcement learning (RL). Exploration has been studied extensively both in theory and in the context of deep RL, and a number of empirically successful methods have been proposed, such as pseudocounts
The approaches above are, however, designed for singleton RL tasks, where the agent is spawned in the same environment in every episode. Recently, several studies have found that RL agents exhibit poor generalization across environments, and that even minor changes to the environment can lead to substantial degradation in performance
Recently, several methods have been proposed which have shown promising performance in PCG environments with sparse rewards, such as RIDE
In this work, we take a closer look at exploration in CMDPs, where each episode corresponds to a different environment context. We first show that, surprisingly, the count-based episodic bonus that is often included as a heuristic is in fact essential for good performance, and current methods fail if it is omitted. Furthermore, due to this dependence on a count-based term, existing methods fail on more complex tasks with irrelevant features or dynamic entities, where each observation is rarely seen more than once. We find that performance can be improved by counting certain features extracted from the observations, rather than the observations themselves. However, different features are useful for different tasks, making it difficult to design a feature extractor that performs well across all tasks.
To address this fundamental limitation, we propose a new method, E3B, which uses an elliptical bonus
Importance and Limitations of Count-Based Episodic Bonuses
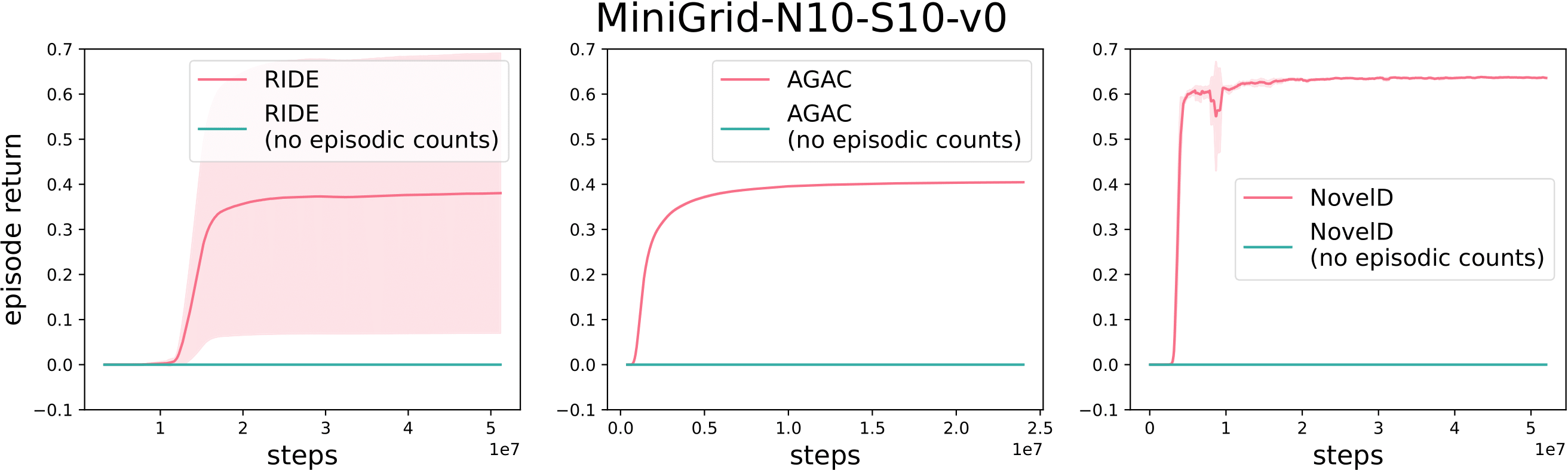
Table 1 shows the exploration bonuses used for RIDE, AGAC and NovelD - three recently proposed methods for exploration which have been applied to the MiniGrid CMDP environment. Note that all three include a term (marked in blue) which depends on episodic counts $$N_e(s)$$. Unlike count-based bonuses which are used in classical tabular RL algorithms, this count-based bonus resets after each episode. Although not presented as a central algorithmic feature, we will show below that these episodic counts are in fact essential for good performance.

Figure 2 shows results for the three methods with and without their respective count-based episodic terms, on one of the MiniGrid environments used in prior work. When the count-based terms are removed, all three methods fail to learn. Similar trends apply for other MiniGrid environments (see our paper). This shows that the episodic bonus is in fact essential for good performance.
However, the count-based episodic bonus suffers from a fundamental limitation, which is similar to that faced by count-based approaches in general: if each state is unique, then $$N_e(s_t)$$ will always be 1 and the episodic bonus is no longer meaningful. This is the case for many real-world applications. For example, a household robot’s state as recorded by its camera might include moving trees outside the window, clocks showing the time or images on a television screen which are not relevant for its tasks, but nevertheless make each state unique. Previous works
Elliptical Episodic Bonuses
In this section we describe Exploration via Elliptical Episodic Bonuses, (E3B), our algorithm for exploration in contextual MDPs. It is designed to address the shortcomings of count-based episodic bonuses described above, with two aims in mind. First, we would like an episodic bonus that can be used with continuous state representations, unlike the count-based bonus which requires discrete states. Second, we would like a representation learning method that only captures information about the environment that is relevant for the task at hand. The first requirement is met by using an elliptical bonus, an idea which has been previously used in the contextual bandit literature
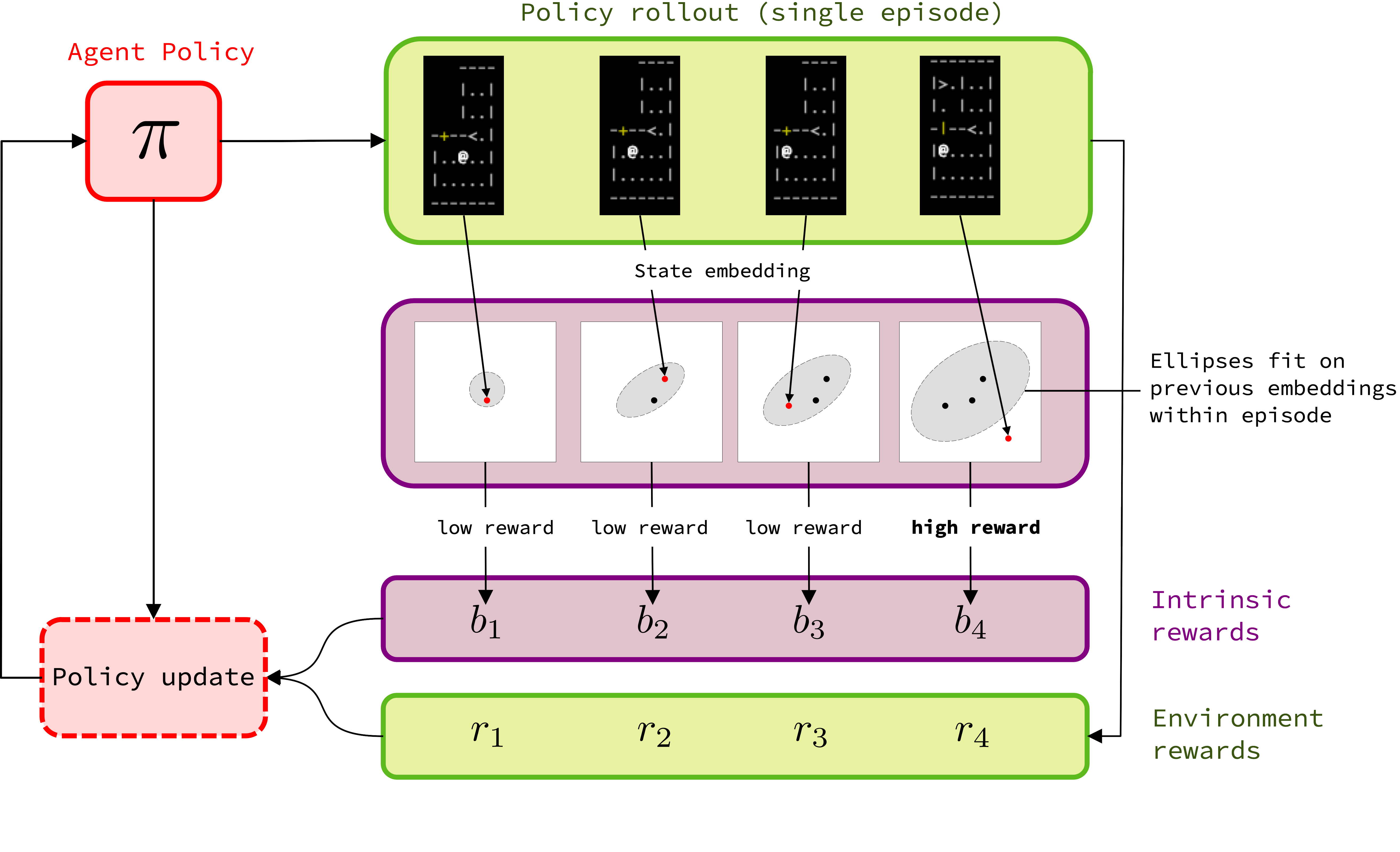
A summary of the method is shown in Figure 3. We define an intrinsic reward based on the position of the current state’s embedding with respect to an ellipse fit on the embeddings of previous states encountered within the same episode. This bonus is then combined with the environment reward and used to update the agent’s policy.
Elliptical Episodic Bonuses
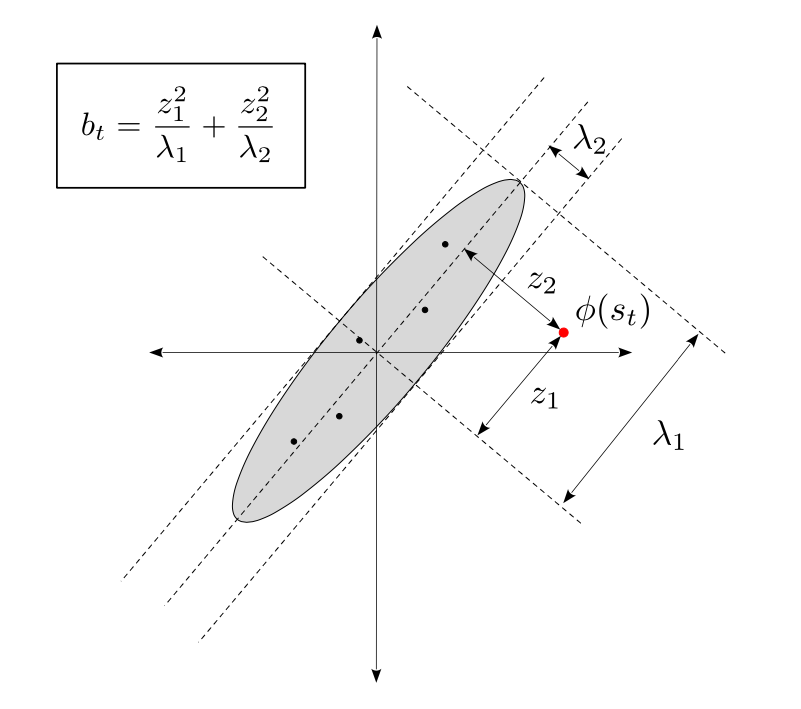
Given a feature encoding $$\phi$$, at each time step $$t$$ in the episode the elliptical bonus $$b$$ is defined as follows:
One perspective which can provide intuition is that the elliptical bonus is a natural generalization of a count-based episodic bonus. To see this, observe that if the problem is tabular and $$\phi$$ is a one-hot encoding of the state, then $$C_{t-1}$$ will be a diagonal matrix whose entries contain the counts corresponding to each state encountered in the episode, and its inverse $$C_{t-1}^{-1}$$ will also be a diagonal matrix whose entries are inverse state visitation counts:
For a more general geometric interpretation, if $$\phi(s_0),...,\phi(s_{t-1})$$ are roughly centered at zero, then $$C_{t-1}$$ can be viewed as their unnormalized covariance matrix. Now consider the eigendecomposition $$C_{t-1} = U^\top \Lambda U$$, where $$\Lambda$$ is the diagonal matrix whose entries are the eigenvalues $$\lambda_1, ..., \lambda_n$$ (these are real since $$C_{t-1}$$ is symmetric). Letting $$z = U\phi(s_t) = (z_1, ..., z_n)$$ be the set of coordinates of $$\phi(s_t)$$ in the eigenspace of $$C_{t-1}$$, we can rewrite the elliptical bonus as:
In practice, inverting the $$C_t$$ matrix at every step would be expensive, but we can use fast rank-$$1$$ updates to circumvent this - see our paper for details.
Learned Feature Encoder
Any feature learning method could in principle be used to learn $$\phi$$. Here we use the inverse dynamics model approach proposed in
Experiments
MiniHack
In order to probe the capabilities of existing methods and evaluate E3B, we seek CMDP environments which exhibit challenges associated with realistic scenarios, such as sparse rewards, noisy or irrelevant features, and large state spaces. For our first experimental testbed, we opted for the procedurally generated tasks from the MiniHack suite

Note the presence of the time counter in the state - this will make each state in the episode unique, and hence will make the episodic count-based bonuses in RIDE, NovelD and AGAC meaningless. In addition to standard baselines (IMPALA, RND, ICM, RIDE, NovelD), we added three variants of NovelD which use hand-engineered features for the count-based bonus instead. NovelD-position extracts the $$(x, y)$$ position from the state and counts, NovelD-message extracts the message, and NovelD-image extracts the symbolic image. We expect these to be stronger baselelines than standard NovelD, since they remove the time counter. However, choosing which features to extract in general relies heavily on domain knowledge.
Results are shown in Figure 4. We report aggregate results across all 16 MiniHack tasks we consider, as well as results broken down by task category: what we call "navigation-based tasks", which involve things like navigating through a series of rooms (with additional challenges such as avoiding lava, opening locked doors or fighting monsters), and "skill-based tasks", which involve using objects (for example, picking up a magic wand, pointing it at a dangerous monster, zapping it, and then exiting the room).
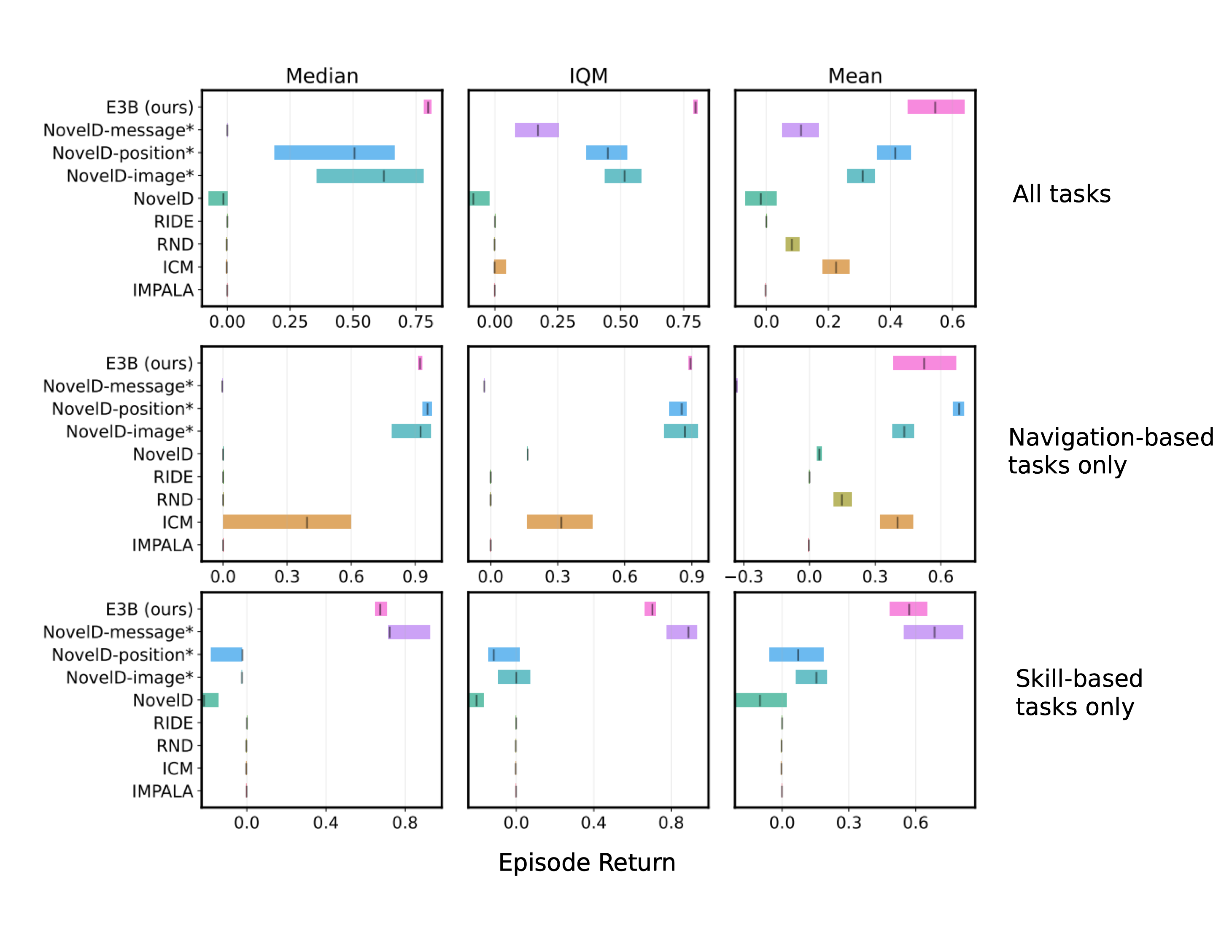
The NovelD variants which use hand-coded features for the episodic bonus perform quite a bit better. NovelD-position obtains excellent performance on navigation-based tasks, which makes sense given that constructing a count-based bonus based on $$(x, y)$$ positions will encourage the agent to visit many different $$(x, y)$$ positions over the course of the episode. However, this approach fails completely on skill-based tasks. This is because the skill-based tasks require doing things like picking up and using objects, which do not require visiting diverse spatial locations, and in this case, counting $$(x, y)$$ locations is not an appropriate inductive bias for the algorithm.
We see an opposite trend for the NovelD-message variant. This version performs very well on skill-based tasks, but much worse than the NovelD-position variant on navigation-based tasks. This highlights that when using the count-based bonus, although certain inductive biases can help for certain tasks, it is difficult to find one which performs well across all of them.
On the other hand, E3B performs well across both the navigation-based tasks and the skill-based tasks, without the need for feature engineering or prior knowledge. Out of all the methods considered, it performs the best across all three metrics
This is illustrated in Figure 5 below. The top row shows the behavior of the three methods on a navigation-based task where the agent must navigate through procedurally-generated rooms surrounded by lava to reach the goal. E3B and NovelD-position both solve the task (interestingly, NovelD-position adopts a policy which tries to maximize the number of $$(x, y)$$ locations visited in addition to reaching the goal). However, NovelD-message does not reach the goal and the agent dies by falling into the lava. This is because counting messages does not provide an intrinsic reward signal which aligns with the true reward. The second row shows the behavior of the three methods on a skill-based task, where the agent must first pick up and drink a levitation potion which will allow it to float in the air above the lava separating it from the goal. Here NovelD-position moves around but does not pick up the potion - indeed, doing does not provide it with any intrinsic reward since its intrinsic reward is constructed by counting $$(x, y)$$ locations visited. NovelD-message is able to solve the task, since picking up and drinking the potion produces novel messages of the form "f - a swirly potion", "What do you want to drink?" and "You start to float in the air!", which provide the agent with intrinsic reward.
In contrast, E3B is able to solve both the tasks, without the need for task-specific inductive biases. One explanation for its success is the following: the position information of the agent is useful for predicting movement actions, while messages are useful for predicting actions such as picking up or using objects. Therefore, it is likely that both types of information are encoded in the features extracted by the inverse dynamics model encoder.
VizDoom
As our second evaluation testbed, we used the sparse reward, pixel-based VizDoom
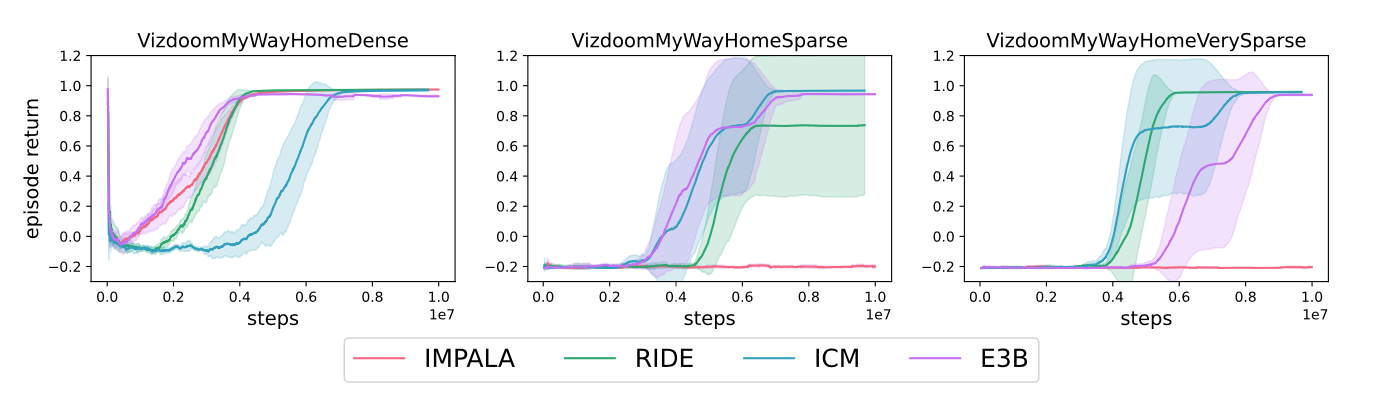
We emphasize that these are singleton MDPs, where the environment does not change from one episode to the next. Therefore, it is unsurprising that ICM, which was designed for singleton MDPs, succeeds in this task. RIDE is also able to solve the task, consistent with results from prior work
Reward-free Exploration on Habitat
As our third experimental setting, we investigate reward-free exploration in Habitat
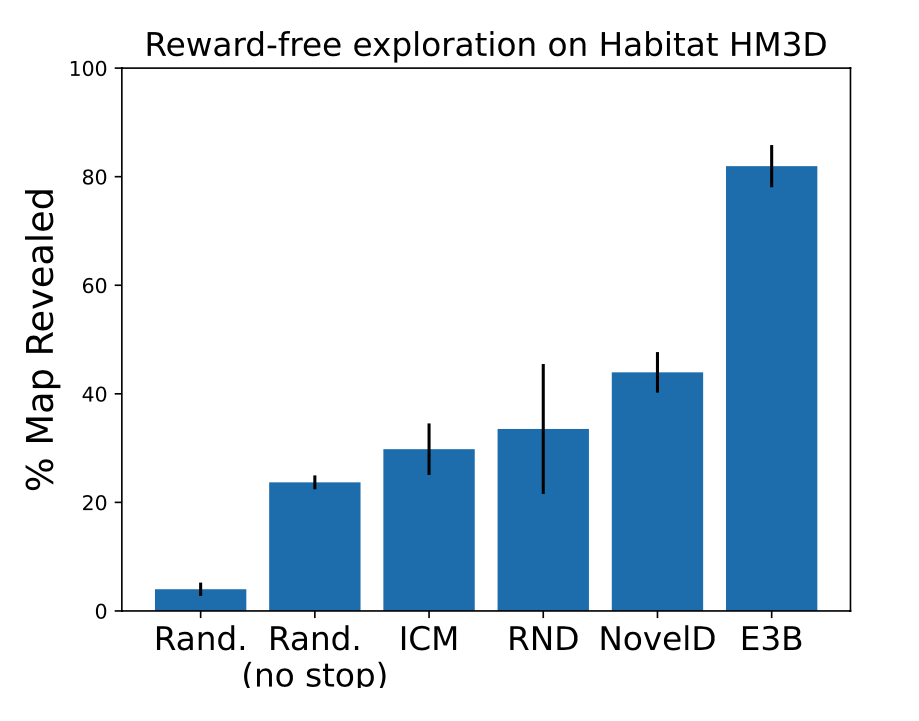
Here we train RND, ICM, NovelD and E3B agents using the intrinsic reward alone, and then evaluate each agent (as well as two random agents) on unseen test environments by measuring how much of each environment has been revealed by the agent’s line of sight over the course of the episode.
Quantitative results are shown in Figure 4, which shows that the E3B agent reveals significantly more of the test maps than any of the other agents.
Below is an example of the behavior of each of the agents. We see that the E3B agents efficiently explores most of the map, while the other agents do not. These results provide evidence for E3B’s scalability to high-dimensional pixel-based observations, and reinforce its broad applicability.
Conclusion
In this work, we identified a fundamental limitation of existing methods for exploration in CMDPs: their performance relies heavily on an episodic count-based term, which is not meaningful when each state is unique. This is a common scenario in realistic applications, and it is difficult to alleviate through feature engineering. To remedy this limitation, we introduce a new method, E3B, which extends episodic count-based methods to continuous state spaces using an elliptical episodic bonus, as well as an inverse dynamics model to automatically extract useful features from states. E3B achieves a new state-of-the-art on a wide range of complex tasks from the MiniHack suite, without the need for feature engineering. Our approach also scales to high-dimensional pixel-based environments, demonstrated by the fact that it matches top exploration methods on Vizdoom and outperforms them in reward-free exploration on Habitat. Future research directions include experimenting with more advanced feature learning methods, and investigating ways to integrate within-episode and across-episode novelty bonuses.